
This Fall I had the opportunity to advise a student’s senior project! She wanted to study “dimension reduction” which, broadly speaking, consists of taking a large set of data and making it smaller, in various clever ways. I think this could be added to a linear algebra class for a nice real life application.
I was excited to do this because I’ve always wanted to learn a little about data science, but also data science is especially good to know for a mathematician who does not have a tenure track position. To finalize my understanding of what we did I want to try to explain it here. The first thing I learned is that data scientists, just like statisticians, seem to use unnecessary language so I will do my best to write what math people might say instead of what a data scientist would say.
Data is sought after and vacuumed up at alarming rates nowadays. Data can really be any piece of information about something. We want to consider a bunch of data, i.e. pieces of information, about a bunch of things, all at once. One very efficient way to do this is to use matrices. For example, we might ask 2 people (things), for 5 pieces of information:
Person A:
– 6 feet tall
– 190 pounds
– 33 years old
– Likes pineapple on pizza
– Single
Person B:
– 5 feet 4 inches tall
– 140 pounds
– 32 years old
– Does not like pineapple on pizza
– Not Single
We can then write the data in a 

Excuse the crude paint created pictures, but I’ve found this to be much faster than anything else!
There are two data points and in general the number of rows of the matrix is the number of data points. Meanwhile there are 5 “features” that encompass each data point, but really this is the number of columns. Oddly, the number of features is also called the dimension of the data set, even though dimension of a matrix already means the number of rows times the number of columns. To summarize: we can either say there are 5 columns, 5 dimensions, or 5 features to this data set, and that there are 2 data points or 2 rows.
With this mini example the term “dimension reduction” may seem obvious. Dimension reduction involves taking a large set of data represented as a matrix with many columns, and transforming it into a matrix with fewer columns. Of course, there are many ways to make a bigger matrix smaller, but we want to do it in a useful way!
When you google “Principal Component Analysis” or “PCA” you find that it’s a pretty simple way of reducing the dimension of a matrix. However, it took me a while to understand why it was a good way to reduce dimension, so that’s what I want to explain.
To this end let’s just think about two dimensional data, and let’s think about how we could reduce it to one dimension in a smart way. Since we are thinking about two dimensional data this means the data can be written as a matrix with two columns:

We can visualize this set of two dimensional data simply by plotting it as a set of points 


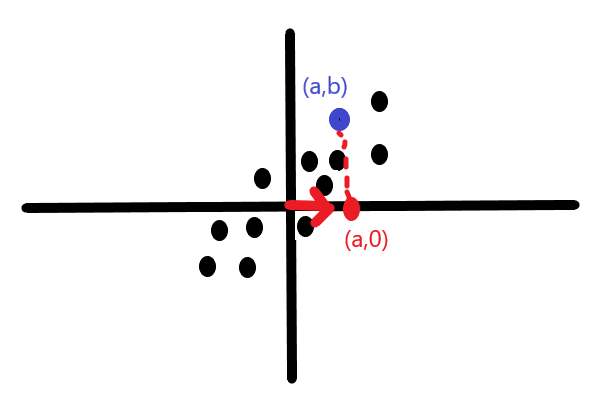
Additionally, let’s highlight one data point in particular and call it 


Right now, each data point is represented using the “standard basis vectors,” which are (1,0) and (0,1). This just means we can think of 

If we reduce the dimension of the data set to a single dimension this really means we’ll only have one basis vector with which to write not just 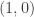
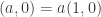
This is not a very good approximation of the data point
So what would a good approximation be? We’ve already hinted at it in the previous paragraph by using the word “near.” We want the transformed data to still be near the original data, so we should minimize the total amount of distance from the original data points. At the same time we want the transformed data to fall on a straight line so that a single basis vector can approximate all of the data. This is the same as projecting the data onto the “best fit line” by definition of the best fit line! It’s the line that is closest to all of the data at the same time:

To project the data onto the best fit line we just need some basic skills picked up in linear algebra. Scale the unit vector, which we call 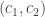

Thus the original data point 

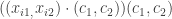
Additionally, since each of the approximations is just a scalar multiple of 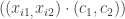

This reveals the dual way of thinking about what this transformation of the data does. The transformed data points are now just numbers living in one dimension, and they are all quite spaced apart! In fact, they are as spaced out as possible in the following sense. If we used any other unit vector besides the one pointing in the direction of the best fit line, the resulting numbers would be less spread out. The amount of spread for a given set of numbers can be measured in several ways, but we use “variance.” Thus, by dotting our data with the unit vector pointing in the direction of the best fit line, the transformed data has maximal variance. This viewpoint is the one we take when extending the ideas into higher dimensions.
Suppose now that we do not want to reduce dimension, and instead we want to look at our data in two dimensions, but from a different perspective. This means we need a second basis vector with which to express the data besides the “best” one from before:
We want the vector to still maximize variance, while at the same time being orthogonal to 

This projects the data to one dimension again, but this time by dotting with 


In terms of matrices we are doing:

So the simple idea behind PCA is to find these “best” vectors

then we can project onto one dimension by doing matrix multiplication 

and the result will be a matrix with only one column. This column is the transformed data and it’s one dimensional, so just a single column of numbers like before, written in terms of the basis vector c:

We want this resulting single column of data to have maximal variance. Recall that the variance of a bunch of numbers is given by averaging their square distance from the mean. Since we are working with standardized data the mean is 0 so the variance of

and we want this to be maximized. We can think of 

The middle matrix, 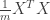



Name each column of 

which is called the variance-covariance matrix of 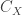
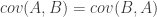

Since 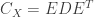


has the corresponding eigenvalues as the diagonal entries and 0’s elsewhere. An additional nice property is that 



Since 
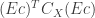
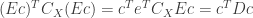

Now since 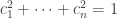

can be at most 
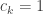
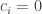

is maximal and equals

into

then you should use the eigenvector:
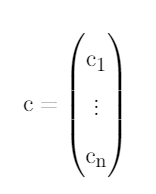
corresponding to the largest eigenvalue of:

and this

to help you get a second dimension. Following the same kind of logic, that is, wanting to maximize resulting variance, we choose
In general the result of PCA is that the matrix 



Then, to reduce the dimension of X to from dimension n to dimension k we simply keep only the first k columns of Y:

We can then think about how much of the original total variance of the data from

The sum of the diagonals of a matrix has a name! It’s called the “trace” of the matrix. The trace happens to also equal the sum of the eigenvalues of the matrix, so we can say that the total variance of 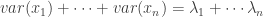






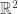 and
and 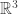 . They either define fields and vector spaces immediately or take a chapter to draw lots of nice pictures. Then they point out some neat little axioms that just so happen to be true in
. They either define fields and vector spaces immediately or take a chapter to draw lots of nice pictures. Then they point out some neat little axioms that just so happen to be true in  and
and  .”
.” is linearly independent you LET
is linearly independent you LET and then SHOW that
and then SHOW that  .
. ”
”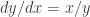

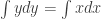
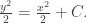
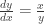

 is a map from the category C to the category D that does the following. For any object X in C, there is an object F(X) in D. For any morphism between objects X,Y in C,
is a map from the category C to the category D that does the following. For any object X in C, there is an object F(X) in D. For any morphism between objects X,Y in C,  there is a corresponding morphism
there is a corresponding morphism 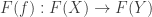 which obey some rules to be explained later. For now just see how this functor is taking objects to CORRESPONDING objects in D, and paths between objects to paths between CORRESPONDING objects in D. What other rules do I need? Well if you will recall from the previous article, a category is not just objects and morphisms. It had some special rules about these things. Remember that for any object X in a category C there has to be at least this one special morphism; the identity morphism
which obey some rules to be explained later. For now just see how this functor is taking objects to CORRESPONDING objects in D, and paths between objects to paths between CORRESPONDING objects in D. What other rules do I need? Well if you will recall from the previous article, a category is not just objects and morphisms. It had some special rules about these things. Remember that for any object X in a category C there has to be at least this one special morphism; the identity morphism  which was like taking the path from X to X by not moving. In the current analogy, I can go from California to California by doing nothing at all. Since C and D are both categories, they both have these special “do nothing” paths and so logically it would be best if we took the one from C and sent it to the one in D. So our first condition for the functor F is that
which was like taking the path from X to X by not moving. In the current analogy, I can go from California to California by doing nothing at all. Since C and D are both categories, they both have these special “do nothing” paths and so logically it would be best if we took the one from C and sent it to the one in D. So our first condition for the functor F is that 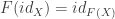 . This is merely saying that F takes in the identity morphism from X to X, and sends it to the identity morphism from F(X) to F(X), which is the object in D that corresponded to X in C via the functor.
. This is merely saying that F takes in the identity morphism from X to X, and sends it to the identity morphism from F(X) to F(X), which is the object in D that corresponded to X in C via the functor. 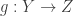 to make one longer morphism
to make one longer morphism 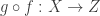 . So let’s see how this works with our functor going from one category to another. First, this requires 3 objects in C. Call them X,Y, Z. If we go from X to Y via the morphism f we can use the functor to make a corresponding path from F(X) to F(Y) via F(f) and if we go from Y to Z via g we can make a corresponding path from F(Y) to F(Z) via F(g).
. So let’s see how this works with our functor going from one category to another. First, this requires 3 objects in C. Call them X,Y, Z. If we go from X to Y via the morphism f we can use the functor to make a corresponding path from F(X) to F(Y) via F(f) and if we go from Y to Z via g we can make a corresponding path from F(Y) to F(Z) via F(g).  so what we really want is to be able to put the corresponding morphisms F(f) and F(g) together in a way that makes sense. Since
so what we really want is to be able to put the corresponding morphisms F(f) and F(g) together in a way that makes sense. Since 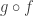 to a functor between F(X) and F(Z). We can then write that
to a functor between F(X) and F(Z). We can then write that  . But now think about what F does to f and g separately. We have
. But now think about what F does to f and g separately. We have  . These are two morphisms with a common middle object, F(Y), in the category D, so of course we are allowed to stick them together to get
. These are two morphisms with a common middle object, F(Y), in the category D, so of course we are allowed to stick them together to get  . We now have two morphisms living in D that go from F(X) to F(Z). Would it make sense that they are secretly the same? Yes my dear Watson it would.
. We now have two morphisms living in D that go from F(X) to F(Z). Would it make sense that they are secretly the same? Yes my dear Watson it would. 
 and
and  , where
, where 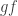 .
.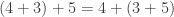 . The idea is simple, we can add the first two numbers together, then add that result with the third or we can add the second and third together and put that with the first. It also works with multiplication:
. The idea is simple, we can add the first two numbers together, then add that result with the third or we can add the second and third together and put that with the first. It also works with multiplication:  .
.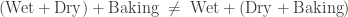
 from B to C,
from B to C,  from C to D, it shouldn’t matter how we make up the big arrow from A to D. Putting
from C to D, it shouldn’t matter how we make up the big arrow from A to D. Putting 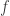 and
and 
 . Then we can go from A to D by first going through
. Then we can go from A to D by first going through  ) for the sides of a right triangle. If you change one axiom, the Parallel axiom, to say that parallel lines are allowed to cross (like on a sphere),
) for the sides of a right triangle. If you change one axiom, the Parallel axiom, to say that parallel lines are allowed to cross (like on a sphere),
